[힙은 곧 우선순위큐다]
힙은 이진트리 기반의 알고리즘으로 특히, 우선순위큐를 구현하는데 힙을 이용하면 쉽게 구현할 수 있다.
현재 많은 기업이 진행하는 코딩테스트에서 우선순위 큐를 구현하는 문제는 출제빈도가 굉장히 높다.
파이썬에서는 heapq, 자바에서도 자주 쓰이던 PriorityQueue를 모듈로 제공해서
이를 이용하면 최소 힙을 간단하게 구현해낼 수 있다.

Lv.2 더 맵게
[문제 설명]
매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같이 특별한 방법으로 섞어 새로운 음식을 만듭니다.
섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
Leo는 모든 음식의 스코빌 지수가 K 이상이 될 때까지 반복하여 섞습니다.
Leo가 가진 음식의 스코빌 지수를 담은 배열 scoville과 원하는 스코빌 지수 K가 주어질 때, 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 섞어야 하는 최소 횟수를 return 하도록 solution 함수를 작성해주세요.
[조건]
- scoville의 길이는 2 이상 1,000,000 이하입니다.
- K는 0 이상 1,000,000,000 이하입니다.
- scoville의 원소는 각각 0 이상 1,000,000 이하입니다.
- 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다.
[입출력]
| scoville | K | return |
| [1, 2, 3, 9, 10, 12] | 7 | 2 |
[내 풀이]
처음에 힙에 대해 몰랐을때,
기존에 큐를 이용해서 풀어냈는데 정확성은 맞지만 몇시간을 붙잡아도 효율성을 줄이지 못했다.
def solution(scoville, K):
scoville.sort(reverse=True)
answer = 0
if scoville[-1]>=K:
return answer
while len(scoville)>1:
first = scoville.pop()
second = scoville.pop()
scoville.append(first + (second*2))
scoville.sort(reverse=True)
answer += 1
if scoville[-1]>=K:
return answer
break
return (-1)특히 반복문이 돌아갈때 O(n)짜리 sorting이 들어가는게 제일 치명적이라고 생각.
아래와 같이 heapq를 이용한 풀이로 하니 통과할 수 있었다.
def solution(scoville, K):
import heapq
heapq.heapify(scoville)
if scoville[0]>=K:
return 0
num = 0
while len(scoville)>0:
a, b = heapq.heappop(scoville), heapq.heappop(scoville)
heapq.heappush(scoville,a+(2*b))
num +=1
if scoville[0]>=K:
return num
break
if len(scoville)==1:
return -1
제약사항(모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다)에 대해,
if문으로 먼저 제거를 해주면서 테스트케이스에 걸릴 변수를 제거해주었다.
heapq의 heapify는 O(N), heapppush와 heappop은 O(logN)의 시간복잡도를 갖기 때문에
N이 커지면 커질수록 위의 코드(큐)보다 훨씬 빠르다고 할 수 있다.
특히 min(scoville)을 쓰지 않고 최소 힙으로 우선순위 큐를 구현했다는 점에서 scoville[0]으로 인덱싱을 해주면서
효율성을 높일 수 있었다.
def solution(scoville, K):
import heapq
heapq.heapify(scoville)
cnt = 0
while len(scoville)>0:
if scoville[0]>=K:
return cnt
if len(scoville)==1:
return -1
cnt += 1
a = heapq.heappop(scoville)
b = heapq.heappop(scoville)
heapq.heappush(scoville, a + 2*b)
[타 풀이]
내 풀이와 비슷하다.
import heapq as hq
def solution(scoville, K):
hq.heapify(scoville)
answer = 0
while True:
first = hq.heappop(scoville)
if first >= K:
break
if len(scoville) == 0:
return -1
second = hq.heappop(scoville)
hq.heappush(scoville, first + second*2)
answer += 1
return answer우선순위 큐의 형태로 풀만한 각이 보이면 힙을 이용해서 푸는 것이 훨씬 좋을 듯 하다.
Lv.3 디스크 컨트롤러
[문제 설명]
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
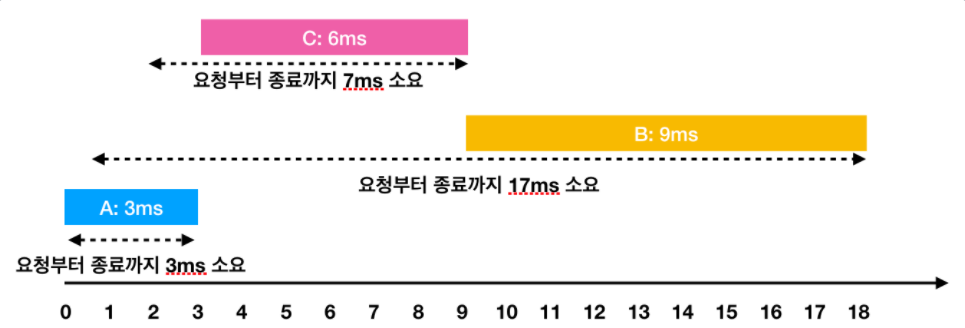
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
[조건]
- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
[입출력]
| job | return |
| [[0, 3], [1, 9], [2, 6]] | 9 |
[내 풀이]
굉장히 어려웠다.
어려웠던 포인트는
1. 제약사항 중 '하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.' 를 어떻게 구현해 낼지가 어려웠고,
2. 요청부터 종료까지 시간을 계산해내는 것 따로, 마지막에 답을 낼 리스트 따로 만들어야 하는데 이런 변수를 어떻게 설정하고 들어가야 하는지가 너무 헷갈렸다.
3. 또 이게 어디서 어떻게 힙을 써야 할지를 모르겠다... 힙으로 분류 안되있었으면 아마 리스트로 접근하다가 시간 많이 날려 먹었을 것 같다.
[타 풀이]
타 풀이도 솔직히 이해가 안가는 것들이 많아 그래도 이해할 수 있었던 코드를 하나 가져왔다.
import heapq
from collections import deque
# tasks = 소요시간(dur), 요청시간(arr)
def solution(jobs):
tasks = deque(sorted([(x[1], x[0]) for x in jobs], key=lambda x: (x[1], x[0]))) #작업구조를 소요시간, 요청시간으로 바꿈
q = []
heapq.heappush(q, tasks.popleft())
current_time, total_response_time = 0, 0
while len(q) > 0:
dur, arr = heapq.heappop(q)
current_time = max(current_time + dur, arr + dur) #전자:곧바로 일 진행될때 , 후자: 멈춰있다가 시작될때
total_response_time += current_time - arr
while len(tasks) > 0 and tasks[0][1] <= current_time: #요청시간이 현재시점보다 짧거나 같으면
heapq.heappush(q, tasks.popleft()) #계속 반복문 돌리면서 q에 넣어주면 소요시간 짧은것대로 q에 들어감(min heap)
if len(tasks) > 0 and len(q) == 0:#요청시간이 현재시점보다 컸을때, 즉 디스크가 작업 안할때
heapq.heappush(q, tasks.popleft())
return total_response_time // len(jobs)1. 먼저 Jobs를 순서를 뒤집어 큐에 넣는다. 뒤집는 이유는 소요시간이 짧은 작업부터 진행시켜야 평균 종료시간을 최소로 맞출 수 있기 때문. 이 이치를 나는 깨닫지 못했고, 이해하는데 시간이 걸렸다. 문제의 예시를 보면서 위의 논리를 끌어낼수 있는 것도 하나의 포인트였던것 같다
2. 그러나 1번의 사실대로만 구현해서는 안된다. 제약사항 중, '하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.' 를 넣어주어야 하기 때문이다. 이는 하드디스크가 놀고 있을때는 소요시간이 짧은 작업이 아니라 남은 작업들 중에서 요청시간이 가장 짧은것을 불러와서 일을 해야하기 때문이다.
3. 요청시간이 현재시점보다 짧거나 같으면 작업을 넣고, 힙에 넣기 때문에 알아서 소요시간이 최소로 되게 자료구조에 들어갈 것이다.
Lv.3 이중순위우선큐
[문제 설명]
이중 우선순위 큐는 다음 연산을 할 수 있는 자료구조를 말합니다.
명령어수신 탑(높이)
| I 숫자 | 큐에 주어진 숫자를 삽입합니다. |
| D 1 | 큐에서 최댓값을 삭제합니다. |
| D -1 | 큐에서 최솟값을 삭제합니다. |
이중 우선순위 큐가 할 연산 operations가 매개변수로 주어질 때, 모든 연산을 처리한 후 큐가 비어있으면 [0,0] 비어있지 않으면 [최댓값, 최솟값]을 return 하도록 solution 함수를 구현해주세요.
[조건]
- operations는 길이가 1 이상 1,000,000 이하인 문자열 배열입니다.
- operations의 원소는 큐가 수행할 연산을 나타냅니다.
- 원소는 “명령어 데이터” 형식으로 주어집니다.- 최댓값/최솟값을 삭제하는 연산에서 최댓값/최솟값이 둘 이상인 경우, 하나만 삭제합니다.
- 빈 큐에 데이터를 삭제하라는 연산이 주어질 경우, 해당 연산은 무시합니다.
[입출력]
| operations | return |
| ["I 16","D 1"] | [0,0] |
| ["I 7","I 5","I -5","D -1"] | [7,5] |
[내 풀이]
import heapq
def solution(operations):
answer = []
min_queue = []
max_queue = []
push_cnt = 0
pop_cnt = 0
for opr in operations:
moving, much = opr.split(' ')[0],int(opr.split(' ')[1])
if moving=='I':
push_cnt+=1
heapq.heappush(min_queue, much)
heapq.heappush(max_queue, -1*much)
else:
pop_cnt+=1
if much==-1:
if len(min_queue)==0:
continue
heapq.heappop(min_queue)
else:
if len(max_queue)==0:
continue
heapq.heappop(max_queue)
if push_cnt>=len(min_queue)+len(max_queue):
return [0,0]
else:
final_queue = sorted(list(set(min_queue)&set(map(lambda x: -x, max_queue))), reverse=True)
answer.extend([final_queue[0], final_queue[-1]])
return answer
min과 max를 따로 저장할 빈 힙을 만들어줘야 하고,
그렇게 했을때 삽입과 삭제에 대한 이슈([0,0]을 내야할 경우 등)에 대응할 코드를 짜는 것이 핵심이라고 생각한다.
'B > Coding Test' 카테고리의 다른 글
| [프로그래머스] 정렬 - 가장 큰 수 (0) | 2021.08.08 |
|---|---|
| BFS/DFS (0) | 2021.04.23 |
| [프로그래머스] 스킬트리 (0) | 2021.02.08 |
| [이코테 2021] 그리디 & 구현 (0) | 2021.01.24 |
| [프로그래머스] 큐/스택 - 프린터 (0) | 2021.01.21 |

